
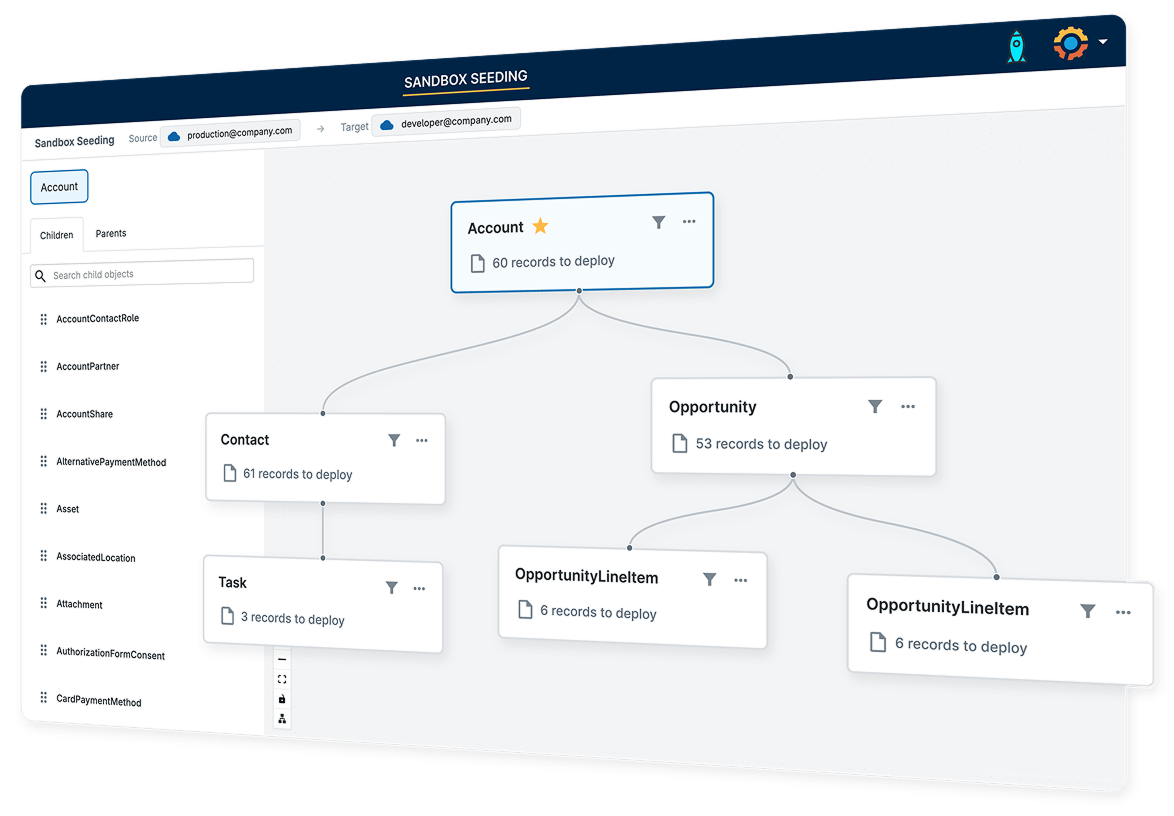










Sandbox seeding is the process of populating a Salesforce sandbox with production data for testing and development. Rather than manually creating test records or relying on mock data, seeding copies real records — including complex relationships and dependencies — into lower environments, giving development teams and QA testers realistic data to work with. Gearset’s Sandbox Seeding solution streamlines this process with built-in data masking, automated dependency mapping, and reusable templates.
Arrange a tailored demo with our DevOps experts. Kick off the process with a 15-minute call to discuss your requirements.
Contact us
Customer support
Talk to an expert in minutes with a 4.9/5 customer happiness rating.
