

Salesforce customer data often sprawls across clouds, apps, and integrations, leaving teams with duplicate records, patchy profiles, and reporting that feels harder than it should. When that starts slowing down personalization, analytics, or cross-team work, implementing Data 360 becomes the obvious next move. There are two big questions you need to ask when it comes to implementing Data 360 into your Salesforce org: what will it cost, and how long will it take?
Unlike other Salesforce products with per-user pricing, Data 360 charges based on how much data you use. This can make budgeting for Data 360 unpredictable, especially if you’re used to fixed licensing models.
Timelines also vary. A simple setup might take a few weeks, but larger enterprise projects can stretch over several months. Your implementation timeline depends on how complex your setup is, how clean your data is, and what resources you have available.
In this article, we’ll break down the cost model and each stage of Data 360 implementation to help you plan realistically. You’ll see how consumption credits work, what factors push costs up, and what to expect across each phase — from setup and identity resolution through to activation. You’ll also learn which architecture choices have the biggest impact on how long the implementation process takes, so you can plan properly and avoid delays that disrupt your schedule or budget.
What is Salesforce Data 360?
Salesforce Data 360 (rebranded from Salesforce Data Cloud at Dreamforce 2025) is Salesforce’s platform for bringing all your customer data together in one place. It connects data from your CRM and external systems, unifies it into reliable profiles, and makes it easy to segment, analyze, and activate that data across the rest of your Salesforce stack. In practice, Data 360 gives teams a single, trusted view of every customer — and the tools to turn that data into real outcomes.
TDX
Understanding Data 360 costs
Data 360 pricing works differently to per-user pricing models. Instead of predictable per-user licenses, there are three factors: consumption credits that track every action, data storage fees based on how much you store, and optional add-ons for advanced features.
Understanding these three areas will help you plan accurate budgets, but because the model is consumption-based, you’ll need to monitor usage closely to avoid unexpected costs.
The three components of Data 360 pricing
Your Data 360 bill combines three main charges, each calculated separately:
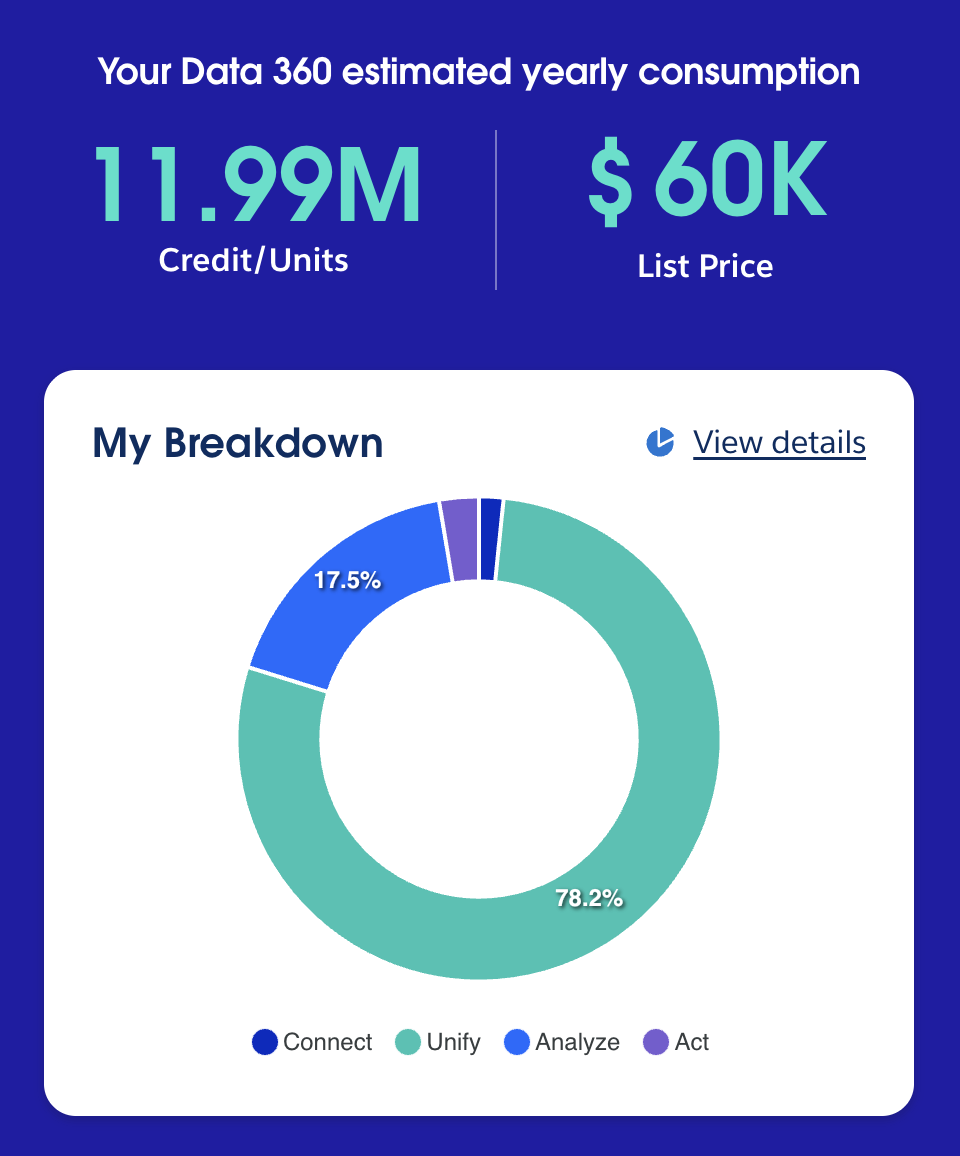
Consumption credits are the foundation of your costs. They track every operation in Data 360, bringing in data from external sources, unifying customer profiles across systems, running queries and calculations, and publishing segments to other platforms. You purchase these credits in shared pools, which can be used across all features — there’s no separate pricing tied to individual actions.
Data storage is charged at a flat $23 per terabyte each month. This covers everything stored in Data 360, from raw data to unified profiles. Storage costs are predictable — 10TB will cost $230 monthly.
Premium add-ons unlock extra capabilities at fixed annual prices. Data Spaces ($60,000/year) lets you partition data by brand or region. Data 360 One ($60,000/year for one connection) supports cross-org connections. Private Connect ($600 per connection) provides secure network links.
How consumption credits work
You buy Data 360 credits in bundles of 100,000 for $500 (with discounts if you’re on an enterprise plan). Every action in Data 360 uses credits — but some tasks use barely any, while others are much more expensive. That’s why monitoring usage is so important.
At a high level, Salesforce groups credit usage into three main areas:
- Connect and Harmonize: covers bringing data into Data 360 and turning it into usable customer profiles.
- Analyze and Predict: is the credit spend for generating insights and running AI over your unified data.
- Act: is the cost of activating your data into downstream systems and real-time use cases.
Three buying models for consumption credits
Salesforce gives teams three commercial models for purchasing consumption credits, depending on how predictable your usage is.
Pre-purchase. You commit to a set number of credits upfront for the full contract term, usually at the lowest price per credit. Your credit balance decreases as you consume services throughout the year. This model suits teams with consistent, high-volume workloads.
Pay-as-you-go. There’s no upfront commitment — you simply pay monthly for what you use. The rate per credit is higher, but you get maximum flexibility. Teams exploring Data 360, running proofs of concept, or handling seasonal peaks often start here to benchmark their usage.
Pre-commit. A hybrid option. You agree to a minimum annual spend (unlocking better pricing) while still having the freedom to scale beyond it. This is typically negotiated directly with your Salesforce account executive, and works well for teams that expect growth but don’t yet have fully stable workloads.
In practice, organisations with predictable, always-on data processing typically benefit most from pre-purchase, while teams still validating their Data 360 strategy often opt for pay-as-you-go before committing.
Self-serve calculations vs. Salesforce guidance
Your Data 360 costs will ultimately be set with your Salesforce account executive, but some elements are easy to estimate yourself. The Data 360 Pricing Calculator can also give you a ballpark figure for credit usage.
For anything beyond that, you’ll need to speak with your Salesforce account executive. They can advise on volume discounts, pre-commit pricing options, and architectural decisions that impact cost — such as whether slower batch ingestion is worth the lower credit consumption compared to streaming.
Monitoring consumption to avoid budget surprises
Salesforce’s Digital Wallet shows near real-time credit usage across all categories. Review it weekly to catch which operations are using the most credits, whilst keeping your monthly billing statement as your official source. You’ll often find things you didn’t expect — like a test segment refreshing every hour, or a calculated insight set to stream when it doesn’t need to be.
As of September 2025, Salesforce Data 360 now offers free ingestion of structured Salesforce data from supported internal clouds, including those used by Agentforce apps. With these common CRM sources no longer consuming credits, most of your spend now shifts to non-Salesforce feeds, data transformations, and any high-frequency processing you have running.
It can be tricky to keep track of where your Data 360 credits are being consumed. Some connectors are especially powerful — for example, the YouTube connector can quickly ingest entire playlists — but certain settings, like enabling captions, can burn through tokens much faster than expected. Teams may suddenly find a connector failing with no credits left, simply because a setting was left on.
To avoid budget surprises:
- Use Salesforce’s Digital Wallet to review near-real-time credit usage across all categories.
- Review your wallet weekly to spot highest-consuming operations (e.g., hourly test segments, streaming when batch would do).
- Always treat your monthly billing statement as the official record of what you’ll be charged.
Steps and general timeline for implementing Data 360
Rolling out Salesforce Data 360 follows a clear set of phases, but timelines can vary widely depending on your data quality, the number of systems you’re connecting, and how many people you have working on the project.
Three things shape your timeline more than anything else:
- How many data sources you have — and how clean they are
- The level of technical support available (admins, analysts, data engineers)
- The scope of what you want to achieve, from simple segmentation to full identity resolution across systems
Planning
Every successful implementation starts with discovery. This is where you define your use cases, map out the systems involved, and agree on your data governance policies.
Key decisions include:
- Whether to use an existing Salesforce org or provision a new one
- Which data sources to bring into Data 360 first
- Your identity resolution approach
- Governance, privacy, and security requirements
This phase brings multiple teams together. IT provides access and credentials, marketing outlines segmentation needs, sales identifies activation points, and compliance validates policies like GDPR or CCPA. Skipping this stage usually causes delays later — teams often end up reworking their data model or rewriting matching rules once they discover gaps.
Data connection and ingestion
Connecting data is usually the longest part of a Data 360 rollout. Even with Salesforce’s large library of pre-built connectors, each source still needs manual configuration. For Salesforce CRM, that means selecting objects and fields, mapping them to the Customer 360 Data Model, setting up permission sets, and choosing sync frequency.
For external systems like Snowflake, S3, or Google Cloud Storage, setup involves authentication, network access, IP allowlists, schema mapping, and planning the initial historical load.
Data quality is often the biggest blocker. Expect to hit issues like inconsistent formats, missing values, duplicate records with conflicting fields, or custom objects that don’t map neatly across systems. Most teams underestimate how much time they’ll spend on data cleanup.
Data modeling and harmonization
Before Data 360 can do anything useful, your raw data needs to be mapped into the Customer 360 Data Model. That means aligning your source fields to core objects such as:
- Individual (people)
- Account (companies)
- Engagement (interactions)
- Sales order (transactions)
You’ll also need to build calculated fields or transformations to standardize inconsistent values — things like phone number formatting, deriving lifetime value, handling nulls, or merging similar fields from different sources.
These choices have a direct impact on every downstream feature. If email fields aren’t mapped cleanly, identity resolution won’t work. If engagement data is incomplete, your segments won’t return the results you expect. Some teams build test segments early to confirm their model supports real use cases.
Identity resolution configuration
Identity resolution is where duplicate records are merged into unified profiles. You’ll define matching fields, configure exact or fuzzy matching, set source priorities, and decide how conflicting values should be handled.
This process is rarely perfect on the first try. Teams typically:
Build initial rules
Test them on a small dataset
Review the match rates and errors
Refine the rules
Test again at larger scale
What works in a small sample often behaves differently with millions of records. Over-aggressive matching can merge different people, while overly strict rules leave duplicates unresolved. Differences in data quality between systems also add complexity.
Testing and validation
Before go-live, you need to check everything works:
- Unified profiles should contain the correct fields
- Segments should return accurate counts
- Activation should send data correctly to target systems
Use test segments with known expected values. For example, if you know there are 10,000 customers who purchased last month, your segment should reflect that. If it doesn’t, you’ve found a data issue.
Run at least one full end-to-end activation workflow — check field mappings, freshness, and error handling. Performance testing is also important: segments that run instantly on small datasets may slow down or fail entirely when scaled to millions of profiles.
Deployment and enablement
This is the go-live stage. You’ll roll out Data 360 to users, assign permissions, create monitoring dashboards, set up alerts for data usage, and document definitions so everyone has a shared understanding of how data flows through the system.
Training should match the role, for instance:
- Marketers learn how to build and activate segments
- Analysts focus on exploring unified data
- Admins are responsible for maintenance and monitoring
Change management is critical. Users need to understand what data is available, how frequently it updates, and how to use it effectively. You’ll also need ongoing processes for monitoring data quality, reviewing usage, tracking segment performance, and resolving issues.
These phases often overlap — you might start modeling before ingestion is fully complete or configure identity resolution using partial datasets. But rushing usually backfires. Cutting corners creates technical debt that slows everything down.
Managing Data 360 configurations as your implementation matures
Data 360 isn’t a one-and-done setup. As your implementation grows, you’ll refine identity resolution rules, add new data sources, create new segments, and adjust activation flows. Unless you have a structured deployment process, these changes quickly pile up — and you’ll start to see configuration drift and unpredictable behavior.
Why Data 360 changes need version control
Data 360 introduces over 30 new metadata types into your Salesforce org, spanning everything from data streams and connectors to identity resolution rulesets, calculated insights, formulas, data model objects, activation targets, and segment definitions. And these aren’t static assets — they evolve constantly.
Small changes have wide impact:
- Updating a match rule can reshape every unified profile.
- A tweak to a calculated insight can change the results of downstream segments.
- Adjusting activation schedules alters how data flows into tools like Agentforce Marketing.
Without version control, it’s almost impossible to track what changed, who made the change, or why behavior suddenly shifted.
Spreadsheets and manual tracking simply don’t scale. They may work in the first few weeks, but once you’re managing dozens of data streams, hundreds of segments, and multiple team members contributing changes, you lose visibility fast.
Things get riskier when several people are working at once. One person updates identity rules while another edits a calculated insight — without a deployment process, those changes can collide or override one another.
Data 360 needs the same level of governance and version control as Apex, Flow, or any other critical Salesforce metadata. It’s the only way to keep configurations stable as you scale.
How Gearset simplifies Data 360 deployments
Gearset handles Data 360 metadata through Salesforce’s Metadata API, which means you can deploy your Data 360 configuration alongside the rest of your Salesforce metadata. You can compare environments, push updates through a controlled release pipeline, and track every change in Git with full end-to-end visibility.
One of the biggest blockers for teams working with Data 360 is that many components — including Data Streams, Data Model Objects, Data Lake Objects, and Calculated Insights — can’t be deployed as standalone metadata. Salesforce requires them to be packaged inside a Data Kit, which acts as a container for related Data 360 metadata.
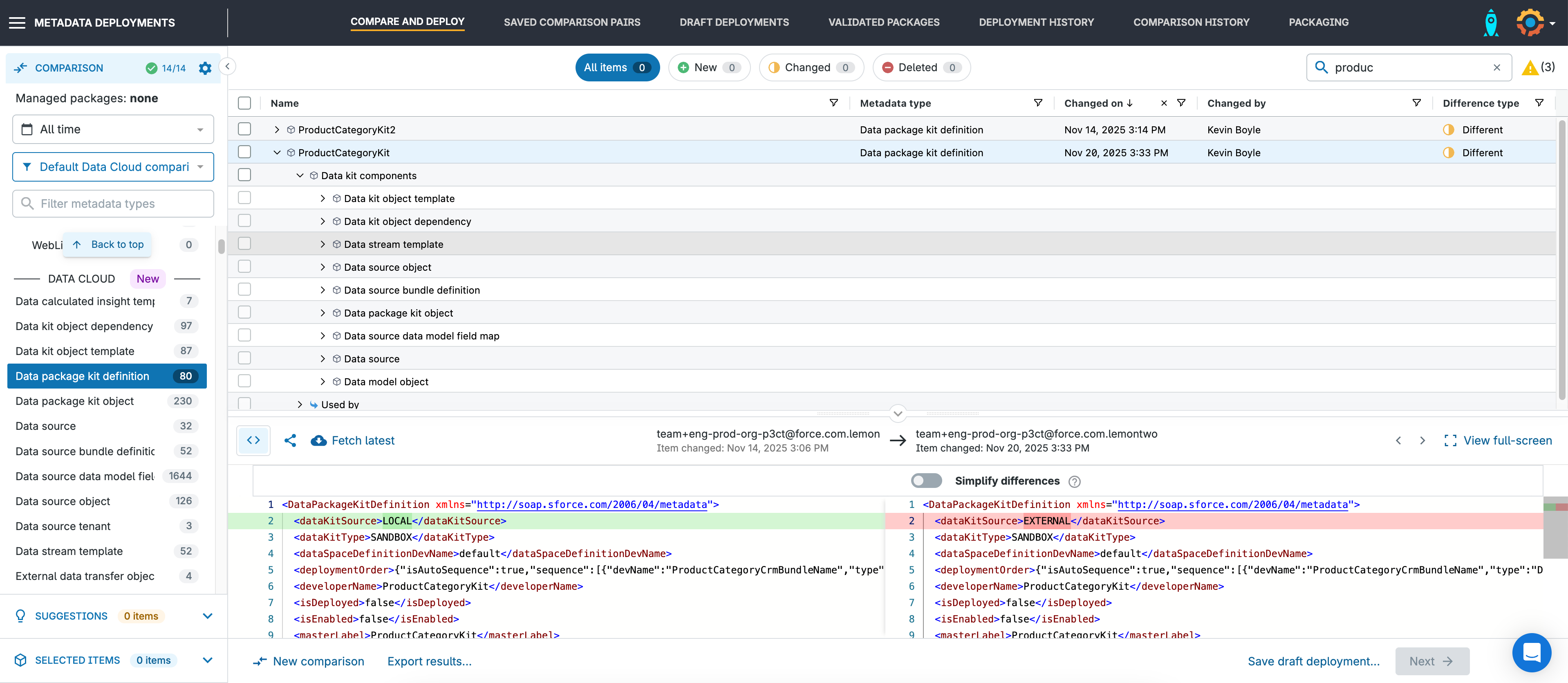
Gearset handles this for you, so you don’t need to manage the packaging rules yourself. Here’s what the workflow looks like in practice:
Easy discovery of Data Cloud components
In the comparison screen, you can use the dedicated Data Cloud tab to quickly filter and select all relevant Data Cloud metadata. Most Data Cloud components must be deployed inside a Data Kit.
Automatic handling of dependencies
When you retrieve a DataPackageKitDefinition, Salesforce doesn’t automatically include the components inside it. Using Gearset’s pre-set Data Cloud filters helps ensure all the required dependent metadata types are selected. If anything is still missing, Gearset’s problem analyzers flag the gaps so you can add the dependencies before validation.
Straightforward validation and deployment
Once your package looks good, Gearset walks you through validation, then deployment to the target environment — treating your Data Kit and Data Cloud components just like any other metadata bundle.
Optional automatic activation
Perhaps the biggest win: Gearset can activate your Data Kit automatically after deployment. On the final summary screen, just enable Activate Data Kits after deployment and Gearset will take care of the post-deployment activation step in the target org — removing yet another piece of manual effort that typically trips teams up.
Together, these capabilities let teams release Data 360 updates alongside Agentforce Sales changes, Agentforce Marketing configurations, and custom code — all through a single, end-to-end pipeline with complete visibility.
This matters because errors in Data 360 are costly. A broken identity rule can create duplicate profiles, and an incorrect activation can push bad data into marketing. With version control and automated deployments, you can avoid these pitfalls and keep delivering at speed — without sacrificing control.
Build confidence in your Data 360 implementation
Implementing Data 360 takes serious time and money. With usage-based pricing, it’s important to keep an eye on consumption to avoid unexpected bills at the end of the month.
The best way to stay on track is to understand what each stage involves. Your planning and architecture choices shape everything that follows. Connecting and cleaning data usually takes longer than expected. Identity resolution needs to be tested and refined multiple times. Testing and user enablement take time and can’t be rushed.
A Data 360 project doesn’t have a fixed endpoint. Business needs will shift, new data sources will be added, and matching rules will need regular updates. Long-term success depends on setting up a flexible foundation that can evolve with your org.
Want to see how Gearset helps manage Data 360 deployments? Book a demo to explore how teams handle Data 360 metadata alongside their wider Salesforce DevOps workflows, or start a free 30-day trial.
