

We’re proud of our engineering culture here at Gearset. We’ve built the sort of team we all want to work in: open, collaborative, laser-focused on quality, pragmatic, and unencumbered with unnecessary process.
This great culture brings a whole host of benefits both to us as engineers, and our users. It enables us to iterate quickly, build the right things at the right times, and deliver real, tangible product improvements week in week out - all without ever compromising on uptime and reliability.
To give one example, we make sure that releasing Gearset to our users is as easy and robust as possible, and work hard to continuously improve that process. We release to production 2-3 times per day and we’re still working to boost that cadence. In this blog post, I’ll dig into the reasons we value being able to release so often, and how we achieve it in practice.
Why is it important to release often?
Both for us and our users, frequent releases deliver a range of advantages.
Short feedback cycles
Short feedback cycles are crucial for enabling a software team to be responsive and agile. The less time it takes to get a change or feature in front of real users, the faster we can get feedback on whether we’re going in the right direction. We constantly use this information to reassess, reprioritize and examine our assumptions.
There’s nothing worse than spending months building a feature and then realizing you’ve built something that doesn’t quite meet the real-world needs of the people you thought would love it. By building in small slices, and releasing those slices to users for feedback as we go, we make sure we’re always doing the most impactful thing possible.
Quicker fixes
Having a high release velocity enables quick fixes. When we notice that something’s not right, the time taken to release a fix is roughly the sum of:
- the time to identify the issue
- the time to create a fix for the issue
- the time to get that fix into our users’ hands
While it’s fairly obvious that the faster we can release, the less time that last bullet point will take, fast releases can also help with identifying and fixing the issue. More on this later.
Forcing us to automate
Releasing multiple times a day soon gets tedious if the process isn’t quick and painless. It forces us to make sure we automate as much as possible. This becomes a virtuous cycle: the more we release, the more pressure there is to automate as much as makes sense; and the more automated the process, the more often we release because it’s easy.
Automation doesn’t just reduce repetitive manual labor and free us up to do more important things. Manual processes are error-prone, but an automated process that’s used multiple times per day becomes battle-tested and trusted. Our release scripts and processes improve incrementally over time, as we learn from mistakes and codify what we’ve learned in our automations.
Small releases
Finally, and most importantly, every release is small because there’s less time for us to build up changes and fixes in the pipeline between each release. Small releases, in turn, yield even more benefits:
- Releasing software always involves some risk. But with smaller releases, each individual release carries less risk, and so is less stressful. With fewer changes being made, there are fewer things that can go wrong each time. Over a given time period, we’ll make the same changes we would have made with bigger releases, if not more. But handling the changes in smaller chunks makes the risks more manageable and easier to mitigate.
- We talked about quick fixes earlier - a small release means that, if anything goes wrong with the rollout, there are a smaller set of changes to inspect to find the root cause. It also decreases the chance that we introduce multiple related issues in the same release. Some of the most complex situations to untangle are when multiple bugs intersect. By minimizing the chance of this happening, we increase the reliability of our software and make fixing issues easier and faster.
The benefits of releasing frequently really matter to us because we make tools that help teams streamline their own release processes on the Salesforce platform. We practice what we preach. All of the philosophies set out in this blog post are baked into the product that we build. Being at the forefront of best practice in our own release process means that we’re well placed to build tools that help our users achieve the same benefits we enjoy.
Who releases?
Anyone on the team. Everyone on the team. We strongly believe it’s important to get everyone on the engineering team involved in releases. In fact, we explicitly set a goal for each new starter to run their own release (with help!) in their first week. We all gain from this in a number of ways:
- If everyone runs releases, everyone is invested in making the release process better. We have to make it easy (and safe) enough that we feel comfortable walking someone through it in their first week.
- Because everyone understands the process, it’s easier to make quick decisions during a release if we need to, without getting bogged down in explaining context or waiting for someone with more knowledge to become available.
- We’re not reliant on particular people being available to run a release.
- Operational issues that hold up releases cause the whole development team pain, which strongly motivates us all to fix those operational issues quickly.
All of this accelerates/increases our release velocity. The more we empower the whole team to own the release process, the more often we can release.
How do we get changes into production?
How do code changes make it from a developer’s machine right through to the point where they’re released to our users? I’ll take you through the process, step by step.
It’s important to note that being able to release on a rapid cadence is as much a cultural problem as a technical one. Most of the things that we do in practice are fairly straightforward - the hard bit is getting buy-in from everyone, at every level of the company, and embedding the process into the way everyone works so that it becomes a habit rather than a conscious effort.
Step 1: Code review
We use a feature branch Git workflow at Gearset. Changes are implemented on short-lived feature branches. We try not to let these branches live more than a week; many last just a few hours. Once a developer is happy with a set of changes on a particular branch (including writing any appropriate automated tests), they submit a pull request and select someone from the team to review their changes. Before being merged, all code must be approved by at least one other member of the team, and all of the automated tests must pass.
Once the code has been approved, it gets merged straight to the master branch. This branch is our source of truth, and is expected always to be in a state ready to release. If we’re not happy to release a change to production, we don’t merge it to master. This means that we’re always in a position to run a release when we want to.
Step 2: Automated tests and staging deployment
This step is completely automated. The newly updated version of master is picked up by our CI process, which runs all of our automated tests and creates a new build of the product.
We don’t normally expect any test failures at this stage, as the tests are also run before merging to master and our branches are short-lived enough that merge problems are rare. However, if there are any problems then a notification is sent to the whole engineering team. Getting the master branch “green” again then becomes a top priority - until the issue is fixed, we can’t release.
Once these tests have passed, the latest build is automatically deployed to our staging environment, which is designed to be as close as possible to our production environment.
Step 3: Manual testing
As soon as a particular change hits staging, the developer that created the pull request in question is notified by our release slackbot. The notification looks something like this:

This is a prompt for the developer to check that everything looks okay with their change on staging. It’s their responsibility to make sure that they’re still happy for the change to be shipped to our users. When they’ve performed whatever manual testing is appropriate, they give the notification a checkmark to show that they’re happy:

Step 4: Pre-checks
When someone wants to run a release, all updates are posted into a dedicated “operations” Slack channel so that the whole company has visibility. The developer runs a command which prompts our release slackbot to list all of the changes that have been merged since the last time the product was released. The bot automatically tags the authors of those changes, and also includes a checkmark next to each item to indicate whether it’s been manually tested by someone (as in the previous step):
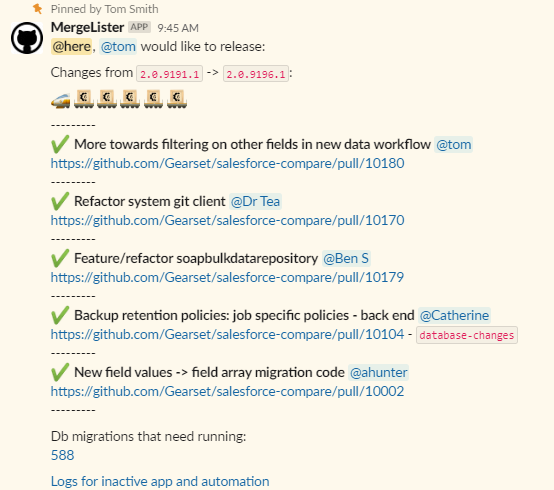
If any of the changes haven’t yet been manually checked, it’s the responsibility of whoever is running the release to make sure any appropriate testing happens before the release starts.
Each item links out to the pull request in question, as useful context for what’s about to be released. The bot also lists any database changes that need to be applied as part of the release, if applicable.
Step 5: The release
Once we’re happy with what’s about to be released, the release itself is very straightforward. There’s a script to run, which asks you which version number you want to deploy. It also posts into the operations channel so that everyone is aware the release is going ahead.
…and that’s it.
Of course, under the hood, there’s a lot going on! Our infrastructure is orchestrated by Kubernetes, and deployments follow a blue-green strategy: new instances of the app are spun up separately from the instances currently running user workloads, and then once all the new instances are healthy we switch all traffic onto the new instances. Old instances stick around to complete jobs they’re already running, and to enable instant rollback (more on that later.) There are safeguards built in to make sure we’re not accidentally trampling any long-running user jobs as part of the release, among other potential pitfalls.
With every past failure, we’ve built what we’ve learned into the process. The beauty of having an automated process is that we don’t have to remember all of this every time - each previous issue has been carefully examined and fixed so that it shouldn’t happen again. Over time, the scripts and the process get more resilient and more reliable.
What if the release has a problem?
We’ve talked a lot about the safeguards baked into every step of the process - from automated testing, to code review, to final manual testing on the staging environment. But, as we all know, there’s no way to guarantee that our new release will be problem-free. Inevitably, releases will occasionally have some sort of issue.
As a result, it’s important that we can respond quickly to and recover from any issue that slips through the cracks. In many cases we can do this before any users even notice a problem.
Finding out something’s wrong
The first step is to realize something is wrong. As a rule, the faster we can do this, the smaller the impact will be. Ideally, we notice an issue before any users are affected at all.
In general, a sign that something’s up comes from one of three sources:
- Alerts: we have a wide variety of alerts set up on our production systems, from warnings about low memory or instance crashes to notifications about certain log messages (or a lack of certain log messages) which may indicate a particular issue. It’s important that these alerts have a low rate of false positives to make sure that when they’re raised, people pay attention and investigate.
- Logs: sometimes we notice an issue by seeing something strange in the logs. Occasionally, this is by chance when we were looking for something else. But normally it’s because we’ve released something that affected a high-risk area of the codebase and we were monitoring the logs carefully to make sure the release was good.
- Customer reports: we have a great relationship with our customers. As a last resort, if anything looks wrong from their perspective and they jump on to the live chat to report it, that request comes straight to a technical member of the team for investigation.
Assessing the situation
Once we suspect there’s an issue with a release, we need to make a decision about how to proceed. In general, the guiding principle is to minimize risk.
Unless we can quickly determine that the issue we’ve seen isn’t related to the release, our default position is to roll back the release immediately . Because of our blue-green deployment strategy, this is instant. Running one script will redirect all new traffic back to the cluster running the previous build. We make sure to write all of our changes in a way that’s both forwards and backwards-compatible with respect to database schema and client changes, which means we can always feel secure doing this.
Having small releases (are you sensing a theme?!) even helps us here. The fact that each release is fairly small means that the user impact of rolling one version back is also fairly small. If we were rolling back a whole month’s worth of feature updates it might be a different story!
Being able to get quickly and safely back to a state we know to be good is invaluable. It gives us time and space so we can critically assess the situation and make sure we proceed in the best possible direction. And it also means we can immediately mitigate the issue for any users currently online.
Fixing the issue
Our next step is to track down and fix the issue. Once again, this is made easier thanks to smaller releases, as there are fewer changes to inspect. Once we’ve made an initial assessment of how difficult the issue will be to fix, we tend to choose one of two approaches:
- If we think it’s going to be an easy fix (and, importantly, if it’s easy to reproduce the issue to make completely sure it is indeed fixed), we usually just make the fix on top of the current
masterbuild and “roll forwards”, releasing the new version once it’s gone through the release pipeline. - If it’s going to be an involved fix, we don’t want to block the release pipeline until we get to the bottom of it, otherwise we’ll be in danger of creating a backlog of changes that turns our next release into a big scary one - exactly what we’ve been trying to avoid! In this case we’ll pull the change that caused the problem out of
master, and clear the pipeline by releasing again without the offending change. Once a fix has been written, we can re-merge the original change along with the fix and continue as normal.
Reflecting
We don’t stop once we’ve fixed the immediate problem, as there’s still a final and important piece of the puzzle to solve. It’s important that we take time to reflect and ask ourselves whether there was anything we could improve about our process as a whole that would have prevented the issue from happening in the first place. Iterative improvement over the whole workflow is the only way to build a truly robust release process.
Constant iteration
Every part of this process is subject to constant iteration. Particularly as we scale the team, we constantly reassess to see if there’s anything we could improve on. Once upon a time (actually not so long ago!), none of the work the slackbot did was automated - we would manually collate a list of changes in each release, and then manually check with each author that they were happy. That worked great with a team of 7, but didn’t really scale to an engineering team of 30+.
I’m sure the process will look different again in another two years, but the core principles - automation, small releases, high release velocity, constant improvement - will still be at its heart.
Sound like the kind of team you’d like to be a part of? We’re hiring! Check out the careers page for more, or shoot us an email at jobs@gearset.com.